How to Bypass Cloudflare Detection


Selenium vs Puppeteer
Selenium and Puppeteer are two widely used browser automation tools that play a crucial role in various scenarios such as webpage testing and data crawling.
Selenium
Selenium is a popular open-source browser automation tool that provides a set of APIs that allow developers to simulate user interaction with the browser.
Pros:
Multi-language support: Selenium seamlessly supports various mainstream programming languages, including Java, C#, Python, and Ruby, providing greater flexibility for developers.
Cross-browser compatibility: Selenium can run on various browsers like Chrome, Firefox, Safari, making cross-browser and cross-platform testing possible.
Rich integration with testing frameworks: Selenium can easily integrate with testing frameworks like JUnit, TestNG, and continuous integration tools like Jenkins.
Robust community support: Selenium has a large community for timely feedback and support for problem-solving and implementation of new features.
Explicit wait function: Selenium provides an explicit wait function that can conveniently handle asynchronous operations.
Comprehensive error handling: Selenium has mechanisms for handling different error situations, providing useful feedback and prompts.
Supports distributed testing: Selenium Grid supports testing simultaneously on different environments and machines.
Test recording: Selenium IDE provides recording and playback functions, which make it easy to create and debug test scripts.
Rich page element location: Selenium supports multiple ways of locating page elements, such as CSS location, XPath location, etc.
Wide application: Selenium is widely used in the automated testing of web applications, and there are plenty of cases and experiences to refer to.
Cons:
Performance overhead: Selenium needs to launch actual browsers for operations, which can consume significant resources and performance.
Older API design: Selenium's API is relatively old, which might need some adaptation for modern development practices.
Weak support for dynamic pages: For single-page applications (SPA) or pages that heavily use Ajax, Selenium might require more complex code to handle.
Requires separate drivers: Each browser requires a corresponding driver, and the installation and maintenance of drivers require additional work.
Requires more resources when running tests concurrently: Selenium consumes more CPU and memory resources when running multiple test cases in parallel.
No built-in screenshot and recording function: Selenium cannot directly record screens and take screenshots, which might be inconvenient in some cases.
Unable to directly control the network: Selenium cannot intercept and modify network requests or simulate offline status.
Unable to execute complex JavaScript: Although Selenium can execute JavaScript, it may have limitations for complex scripts.
Insufficient debugging information: The error information and log output of Selenium might not be detailed enough for debugging.
Puppeteer
Compared to Selenium, Puppeteer is a newer tool developed and maintained by the Google Chrome team. Puppeteer is a Node.js library that provides a high-level API to control Chromium or Chrome through the DevTools protocol.
Though both Selenium and Puppeteer can be used for browser automation, there are some key differences between them. Here are the advantages and disadvantages of Puppeteer.
Pros:
Modern API: Puppeteer's API design is more in line with modern JavaScript programming thinking, using Promise for asynchronous operations, and is easier to understand and control.
Excellent performance: Puppeteer has a significant performance advantage due to its ability to run headless Chrome.
Comprehensive functions: In addition to basic browser automation operations, Puppeteer also supports advanced operations such as webpage screenshots, PDF generation, and network request interception.
Support for SPA: Puppeteer can wait for JavaScript execution, thus better handling single-page applications (SPA) or pages that use Ajax.
Convenient debugging support: Puppeteer provides rich debugging options, such as outputting detailed information during the operation process to the console.
Efficient network control: Puppeteer can intercept and modify network requests, simulate different network conditions, and even simulate offline status.
Support for Chrome features: Puppeteer can utilize all the latest features of Chrome, such as debugging with Chrome DevTools.
Provides rich examples: Puppeteer's official documentation contains a large number of usage examples, covering most common usage scenarios.
Support for page operation recording: Puppeteer can record user operations on the page and generate scripts that can be run directly.
Good error handling: When Puppeteer encounters an error, it provides detailed error information to help developers locate the problem.
Cons:
Language limitation: Puppeteer only supports JavaScript, which might limit its use by some developers.
Browser limitation: Puppeteer only supports Chromium or Chrome, thus it cannot perform cross-browser testing.
Relatively high learning curve: For developers who are not familiar with Promise or Node.js, Puppeteer might require some learning.
Smaller community size: Compared to Selenium, Puppeteer has a smaller community size, so you might not be able to get timely answers when encountering problems.
Compatibility issues with non-Chrome browsers: Since Puppeteer is developed by the Chrome team, there might be compatibility issues when using non-Chrome browsers.
Requires a Node.js environment: Puppeteer is a Node.js library and needs a Node.js environment to run, which might require additional installation and configuration work.
Potential issues with complex DOM operations: Although Puppeteer can execute JavaScript, it might have difficulties with complex DOM operations.
Potential security risks: Puppeteer requires enough permissions to control the browser, which might pose potential security risks.
Insufficient support for older versions of Node.js: Puppeteer needs a newer version of Node.js to fully utilize its features.
Conclusion
Whether to choose Selenium or Puppeteer depends on your specific needs and environment. Both tools have their unique advantages and applicable scenarios.
If you need to perform cross-browser testing, or if your team is already familiar with and using languages like Python, Java, or C#, then Selenium might be a better choice because it supports multiple browsers and languages.
If you need to perform some advanced operations, such as screenshots, PDF generation, network request interception, etc., or if your team mainly uses JavaScript, then Puppeteer might be more suitable for you, as Puppeteer provides more functions and a more modern API.
What is Cloudflare?
Cloudflare is a company that provides CDN services, DDoS attack protection, and internet security services. Cloudflare can help websites speed up page loading, protect websites from malicious attacks, and provide a variety of other optimization and security services.
When users try to access a website using Cloudflare services, their requests are first sent to Cloudflare's network. Cloudflare will analyze the request to determine whether it comes from a legitimate user. Cloudflare uses the following techniques to detect whether a user is a robot:
IP Blacklist
By checking the IP address of the request, Cloudflare can identify known malicious IPs and networks. Cloudflare maintains a large IP database that can identify known sources of spam, malware, etc.
HTTP Request Header Analysis
Cloudflare will check the header information of the HTTP request, such as the User-Agent field, to see if it matches the characteristics of a normal browser. Many automation tools or crawlers may use non-standard or clearly identifiable User-Agents.
Behavior Analysis
Cloudflare will monitor the behavior of visitors, including the frequency of requests, the pages visited, etc. If a visitor's behavior pattern does not match that of a normal user, such as issuing a large number of requests in a short period of time, Cloudflare might consider it a robot.
JavaScript Challenge
Cloudflare will send a piece of JavaScript code to the visitor that needs to be run in the browser, and this code will return a calculation result. Since most robots and crawlers cannot execute JavaScript code, this is an effective detection method.
CAPTCHA Challenge
For suspicious visits, Cloudflare will ask the visitor to solve a CAPTCHA (Completely Automated Public Turing test to tell Computers and Humans Apart). Human users are usually able to solve this challenge, while robots cannot.
SSL/TLS Fingerprinting
By checking the handshake process of the SSL/TLS client, Cloudflare can identify certain malicious tools or known non-browser software.
Can Cloudflare detect Selenium or Puppeteer?
Cloudflare uses a series of complex techniques to identify non-human access behavior. Although it cannot directly identify Selenium or Puppeteer, it can indirectly discover the use of these automation tools by analyzing the characteristics of access behavior. For example, Cloudflare can discover public, known automation tool identifiers by checking the User-Agent field. At the same time, it can identify abnormal request patterns by analyzing request frequency, or find differences in the execution environment of Selenium or Puppeteer through JavaScript challenges.
In addition, Cloudflare may also use WebDriver's special markers to discover the use of Selenium, or identify automated behavior through WebGL fingerprint recognition and mouse and keyboard event analysis. Therefore, if you want to use Selenium or Puppeteer to access websites protected by Cloudflare, you need to simulate real user behavior as much as possible, including setting reasonable User-Agents, adding request intervals, hiding WebDriver markers, etc., to avoid being recognized by Cloudflare as automated behavior.
How to Bypass Cloudflare?
# Method 1: Bypass Cloudflare CDN by calling the origin server
Selenium
Here is an example of using the Python requests library to bypass the CDN via the origin server:
import requests
# This is the IP address of the origin server
source_server_ip = '123.456.789.012'
# This is the URL you want to access
url = 'http://www.example.com'
# Create a new request session
session = requests.Session()
# Create a custom adapter and set the IP address of the origin server as the resolution result
class SourceServerAdapter(requests.adapters.HTTPAdapter):
def get_connection(self, url, proxies=None):
return super().get_connection(f'{source_server_ip}', proxies)
# Mount the custom adapter to the session, it will be used to handle all HTTP and HTTPS requests
session.mount('http://', SourceServerAdapter())
session.mount('https://', SourceServerAdapter())
# Send the request
response = session.get(url)
Copy
Please note, this example assumes you already know the IP address of the source server. If you don't know it, you might need to use other methods to find it, such as conducting a DNS query or using network scanning tools.
Moreover, this example is just one possible solution and may not apply to all situations. For instance, some websites might check the Host header of the request, and if it doesn't match the IP address of the source server, the request might be rejected. In this case, you might need to use other methods to bypass the CDN, such as using a VPN or proxy server.
Puppeteer
To use Puppeteer to bypass Cloudflare CDN and access the source server directly, you need to know the IP address of the source server. Then, you can modify the /etc/hosts file to resolve the domain name of the source server to its IP address. After that, you can use Puppeteer to access the website as usual, and it will connect directly to the source server, not through the Cloudflare CDN.
Here's a possible solution:
1.First, modify the /etc/hosts file by adding a line to resolve the domain name of the source server to its IP address. For instance, if the IP address of the source server is 123.456.789.012, and the domain name is www.example.com, add the following content:
123.456.789.012 www.example.com
2.Then, access the website using the following Node.js and Puppeteer code:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('http://www.example.com');
await page.screenshot({path: 'example.png'});
await browser.close();
})();
Please note, modifying the /etc/hosts file might require administrator privileges and could impact your system's network settings. After finishing your visit, you should restore the /etc/hosts file to its original state.
Besides, this method might not work for all situations. For instance, if the website uses HTTPS, the browser might refuse to access due to a certificate error. In this case, you might need to use other methods to bypass the Cloudflare CDN, such as using a VPN or a proxy server.
# Method 2: Bypass Cloudflare's Waiting Room
Cloudflare's waiting room is a widely used website defense mode to protect websites from malicious attacks and traffic flooding. It usually monitors frequent access behaviors and considers them as potential malicious attacks. Therefore, setting a reasonable access speed and frequency is very important. Adhering to the website's Robots.txt rules and avoiding requesting pages too quickly can reduce the probability of being detected by the protection system.
To bypass the Cloudflare waiting room, you need to make Selenium/Puppeteer behave like a real browser. Here is a simple Python and Selenium code example:
from selenium import webdriver
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
# Start webdriver
driver = webdriver.Firefox()
# Visit the website
driver.get('https://www.example.com')
# Wait for the JavaScript challenge to complete, you can adjust the waiting time
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.ID, 'content')))
# Now you can proceed with your automation process
This code will visit https://www.example.com, then wait for 10 seconds for Waiting Room to complete. The waiting time may need to be adjusted according to the actual situation of the website.
However, please note that this method may not always be effective. Cloudflare's Waiting Room is designed to be very complex, and its purpose is to prevent access by automated tools. If you find that this method does not work, it may be because Cloudflare has updated their mechanism and you need to try other methods.
# Method 3: Bypass Cloudflare CAPTCHA
Cloudflare's CAPTCHA verification is designed to prevent automated scripts and robots from accessing websites, so using Selenium or other automation tools to try to bypass it requires some tricks. In addition to using proxy servers, some third-party services provide APIs for automatically solving CAPTCHAs, and we can use these APIs to bypass the restrictions of Cloudflare CAPCHA.
2Captcha and Anti-Captcha both provide services for automatically solving CAPTCHAs. They use real people to solve CAPTCHAs, and then return the solution to your program. Then, your program can use this solution to continue its automation process.
Below is a Python code example using 2Captcha and Selenium to solve Google reCAPTCHA:
from selenium import webdriver
from time import sleep
import requests
import json
# 2Captcha's API key
api_key = 'your_2captcha_api_key'
# Start webdriver
driver = webdriver.Firefox()
driver.get('https://www.google.com/recaptcha/api2/demo')
# Get the site key of reCAPTCHA
site_key = driver.find_element_by_class_name('g-recaptcha').get_attribute('data-sitekey')
# Send a request to 2Captcha to solve reCAPTCHA
response = requests.post('http://2captcha.com/in.php', data={
'key': api_key,
'method': 'userrecaptcha',
'googlekey': site_key,
'pageurl': 'https://www.google.com/recaptcha/api2/demo',
'json': 1
})
# Get the request ID from 2Captcha
request_id = json.loads(response.text)['request']
# Wait for 2Captcha to solve reCAPTCHA
while True:
response = requests.get(f'http://2captcha.com/res.php?key={api_key}&action=get&id={request_id}&json=1')
result = json.loads(response.text)
if result['status'] == 1:
# Enter the solution into reCAPTCHA
driver.execute_script(f'document.getElementById("g-recaptcha-response").innerHTML="{result["request"]}";')
sleep(2)
driver.find_element_by_id('recaptcha-demo-submit').click()
break
sleep(5)
#Method 4: Use anti-detect browser
Using a fingerprint browser for automated operations may bypass some of Cloudflare's protection mechanisms because these browsers can simulate the browsing behavior and environment of real users. Fingerprint browsers can change or randomize their browser fingerprints, making them look like each visit is from a different, real user. This makes it more difficult for Cloudflare to recognize that these requests are actually generated by automation tools.
However, you need to note that using a fingerprint browser does not guarantee that you can bypass Cloudflare or other similar services. These services continuously update and improve their mechanisms for identifying and blocking automated traffic. Therefore, you also need to combine proxy servers and appropriate scripts to achieve this.
Check Your Scripts
When you use an automation script to pass Cloudflare or to execute some automated task processes, you can use BrowserScan to check whether your script is perfect and check where there are features of automation tools.
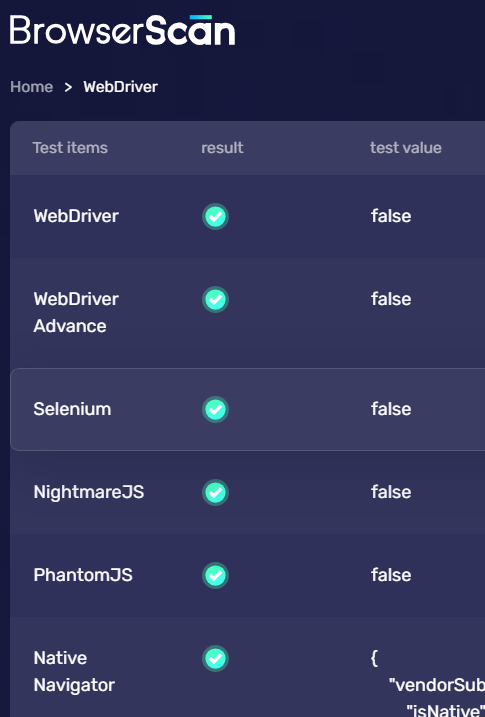
BrowserScan can help you check your scripts from six aspects: Webdriver, Webdriver Advance, Selenium, NightmareJS, PhantomJS, and Native Navigator.
WebDriver
Websites can detect whether users use WebDriver to control the browser, mainly because WebDriver leaves some specific marks or properties when controlling the browser.
For example, by default, when using UI automation tools such as Selenium/Puppeteer to visit web pages, the value of the navigator.webdriver variable is true.
Selenium
This part will detect more browser properties. After using Selenium to open the browser, there will be some feature codes. As long as these feature codes are recognized, the website can identify that the user is controlled by Selenium.
If your automation script does not cover these features well, it will be displayed as "True" in BrowserScan.
webdriver
__driver_evaluate
__webdriver_evaluate
__selenium_evaluate
__fxdriver_evaluate
__driver_unwrapped
__webdriver_unwrapped
__selenium_unwrapped
__fxdriver_unwrapped
_Selenium_IDE_Recorder
_selenium
calledSelenium
_WEBDRIVER_ELEM_CACHE
ChromeDriverw
driver-evaluate
webdriver-evaluate
selenium-evaluate
webdriverCommand
webdriver-evaluate-response
__webdriverFunc
__webdriver_script_fn
__$webdriverAsyncExecutor
__lastWatirAlert
__lastWatirConfirm
__lastWatirPrompt
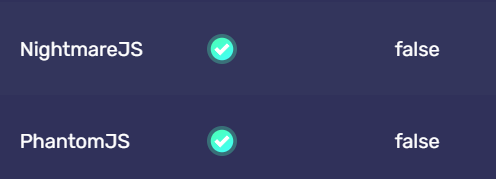
NightmareJS、PhantomJS
NightmareJS: This is a high-level browser automation library built on Electron. It uses the Chromium rendering engine and the Node.js runtime environment. NightmareJS aims to provide a simpler, more user-friendly API, as well as more powerful features, such as support for user interactions (clicking, typing, etc.) and page performance analysis.
PhantomJS: This is a headless browser, it uses the WebKit rendering engine (the same as used by older versions of Safari and other Apple devices) for page rendering, and JavaScriptCore for JavaScript execution. PhantomJS supports various web standards: DOM handling, CSS selectors, JSON, Canvas, and SVG. However, development of PhantomJS stopped in 2018.
BrowserScan will detect whether your script is controlled by these two tools. If it shows "False", it means that you are not currently using these two tools to control the browser, or you have masked the features of the browser automation tools, and BrowserScan has not obtained related information.
Native Navigator
BrowserScan can detect whether the properties of the Navigator object are native methods.
Websites often use the Navigator object to detect whether users are robots:
navigator.userAgent: This property returns a string containing the browser name, version, operating system, and browser engine information. If this string matches the characteristics of automation tools, the website may mark visitors as robots.
navigator.plugins and navigator.mimeTypes: These two properties return a list of plugins and MIME types supported by the browser. Some automation tools may not support any plugins or MIME types, or the list of supported items may differ from normal browsers, which may be used by websites to detect robots.
navigator.cookieEnabled: This property indicates whether the browser has enabled cookies. Some automation tools may disable cookies, which may be detected by websites as robots.
navigator.languages: This property returns the language settings of the browser. If this setting does not match the visitor's geographical location or other browser settings, the website may mark it as a robot.
navigator.doNotTrack: This property indicates whether the browser has set "Do Not Track". Automation tools may enable this setting, which may be detected by websites as robots.
navigator.javaEnabled(): This method returns whether the browser has enabled Java. Automation tools may disable Java, which may be detected by websites as robots.
In addition, some other properties and methods may also be used to detect robots, such as navigator.hardwareConcurrency (returns the logical core number of the CPU), navigator.deviceMemory (returns the size of the device's RAM), etc.
Final Tips
Final tips on bypassing Cloudflare detection
Regularly Update Your Automation Tools: Cloudflare regularly updates its detection algorithms. To bypass detection, make sure your automation tools (like Selenium, Puppeteer, etc.) are up to date.
Imitate Human Behavior: Make your automation script act more like a human. This can include random delays between actions, moving the mouse cursor in a non-linear path, scrolling down a page, and more.
Use Residential Proxies: Cloudflare is more likely to block traffic from data center IPs, which are commonly used by bots. Using residential proxies can help bypass detection.
Rotate Your User Agent: Regularly change the user agent string of your browser. This can help avoid detection as Cloudflare might flag repetitive user agent strings as bot-like behavior.
Avoid Obvious Bot-Like Behavior: Actions like rapidly opening many connections, or making too many requests in a short period of time, can trigger Cloudflare's bot detection.
Handle CAPTCHAs: Use services like 2Captcha or Anti-Captcha to solve CAPTCHAs that Cloudflare might present.
Mimic a Real Browser: Configure your automation tool to mimic a real browser as closely as possible. This includes enabling JavaScript, accepting cookies, and more.